LLMscope
💰 LLMscope - Track Your LLM Costs in Real-Time
Stop guessing what your ChatGPT and Claude API calls cost. Track them in 60 seconds with 3 lines of code.
![]()
🎯 Quick Access
After running docker-compose up -d:
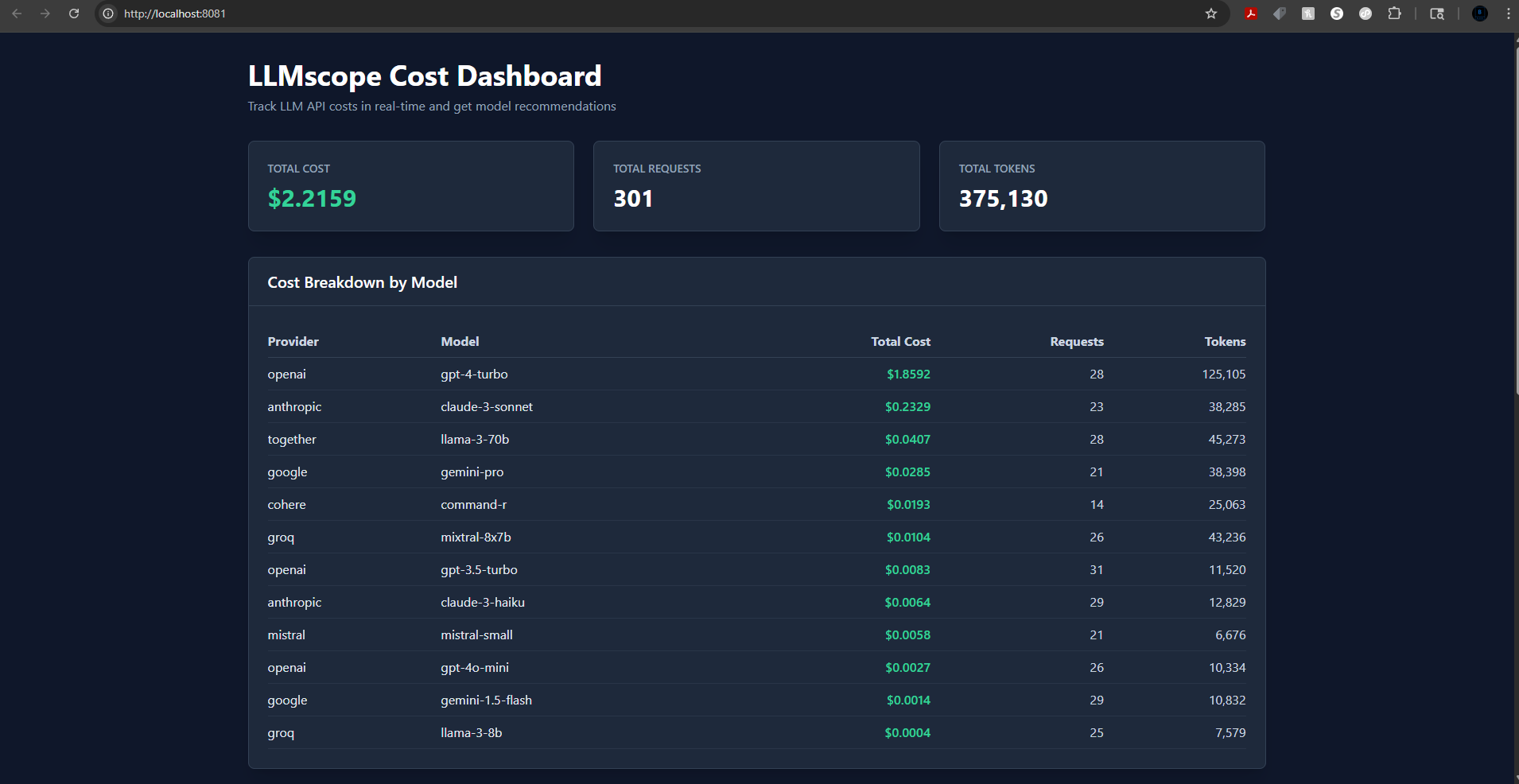
- 🌐 Dashboard: http://localhost:8081 - Cost tracking interface
- 🔌 API: http://localhost:8000 - Backend API endpoints
- 📊 API Docs: http://localhost:8000/docs - Interactive API documentation
🚨 The Problem
LLM API costs are spiraling out of control. You don’t know:
- 💸 How much you’re spending on each model
- 📈 Which providers are most expensive
- 🔄 If there are cheaper alternatives
- 📊 Your usage patterns over time
✅ The Solution
LLMscope gives you complete visibility and control over your LLM costs:
- ✅ Real-time cost tracking - See costs as they happen
- ✅ Cost breakdown - By provider, model, and time period
- ✅ Smart recommendations - Get suggestions for cheaper models
- ✅ Usage analytics - Track token usage and patterns
- ✅ Self-hosted - Keep your data private
🚀 Quick Start (60 Seconds)
Step 1: Deploy LLMscope
Using Docker (Recommended):
git clone https://github.com/Blb3D/LLMscope.git
cd LLMscope
docker-compose up -d
Visit http://localhost:8081 - You’ll see the dashboard (empty until you track your first API call).
Step 2: Track YOUR First LLM API Call
After making any OpenAI, Anthropic, or other LLM API call, add 3 lines to log the cost:
Example: Track OpenAI GPT-4 Call
import openai
import requests
# Your normal OpenAI API call
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello!"}]
)
# Add these 3 lines to track cost:
requests.post('http://localhost:8000/api/usage', json={
'provider': 'openai',
'model': 'gpt-4',
'prompt_tokens': response['usage']['prompt_tokens'],
'completion_tokens': response['usage']['completion_tokens']
})
That’s it! Refresh the dashboard to see your real costs.
Step 3 (Optional): Generate Demo Data for Testing
Want to test the dashboard before integrating your real API calls?
cd backend
python generate_demo_data.py
This creates 100 sample API calls to preview the dashboard features.
📊 Real-World Integration Examples
OpenAI Integration
Track every OpenAI API call:
import openai
import requests
def track_openai_usage(response):
"""Helper function to track OpenAI costs"""
requests.post('http://localhost:8000/api/usage', json={
'provider': 'openai',
'model': response['model'],
'prompt_tokens': response['usage']['prompt_tokens'],
'completion_tokens': response['usage']['completion_tokens']
})
# Use it after any OpenAI call:
response = openai.ChatCompletion.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": "Explain quantum computing"}]
)
track_openai_usage(response)
Anthropic Claude Integration
Track Claude API calls:
import anthropic
import requests
def track_anthropic_usage(model, response):
"""Helper function to track Anthropic costs"""
requests.post('http://localhost:8000/api/usage', json={
'provider': 'anthropic',
'model': model,
'prompt_tokens': response.usage.input_tokens,
'completion_tokens': response.usage.output_tokens
})
# Use it after Claude API calls:
client = anthropic.Anthropic(api_key="your-key")
message = client.messages.create(
model="claude-3-sonnet-20240229",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello, Claude!"}]
)
track_anthropic_usage("claude-3-sonnet", message)
LangChain Integration
Automatic tracking with LangChain callback:
from langchain.callbacks.base import BaseCallbackHandler
from langchain.chat_models import ChatOpenAI
import requests
class LLMscopeCallback(BaseCallbackHandler):
def on_llm_end(self, response, **kwargs):
if hasattr(response, 'llm_output') and response.llm_output:
usage = response.llm_output.get('token_usage', {})
requests.post('http://localhost:8000/api/usage', json={
'provider': 'openai',
'model': response.llm_output.get('model_name', 'gpt-3.5-turbo'),
'prompt_tokens': usage.get('prompt_tokens', 0),
'completion_tokens': usage.get('completion_tokens', 0)
})
# Use with LangChain:
llm = ChatOpenAI(callbacks=[LLMscopeCallback()])
result = llm.predict("What is the capital of France?")
Google Gemini Integration
Track Gemini API calls:
import google.generativeai as genai
import requests
def track_gemini_usage(model_name, response):
"""Helper function to track Google Gemini costs"""
requests.post('http://localhost:8000/api/usage', json={
'provider': 'google',
'model': model_name,
'prompt_tokens': response.usage_metadata.prompt_token_count,
'completion_tokens': response.usage_metadata.candidates_token_count
})
# Use it after Gemini calls:
genai.configure(api_key="your-key")
model = genai.GenerativeModel('gemini-pro')
response = model.generate_content("Write a poem about AI")
track_gemini_usage('gemini-pro', response)
🔧 Manual Setup (Without Docker)
Backend:
cd backend
pip install -r requirements.txt
# Seed the database with LLM pricing data
python seed_pricing.py
# Start the backend
python app.py
Frontend:
cd frontend
npm install
npm run dev
Visit http://localhost:8081
📊 Features
💰 Real-Time Cost Tracking
Track every LLM API call with automatic cost calculation. Monitor spending across 63+ models from OpenAI, Anthropic, Google, Cohere, Together AI, Mistral, Groq, and more.
- Instant cost visibility - See exactly what each request costs
- Provider comparison - Compare costs across different LLM providers
- Token usage analytics - Track prompt and completion tokens
- Auto-refresh - Dashboard updates every 5 seconds
💡 Smart Cost Optimization
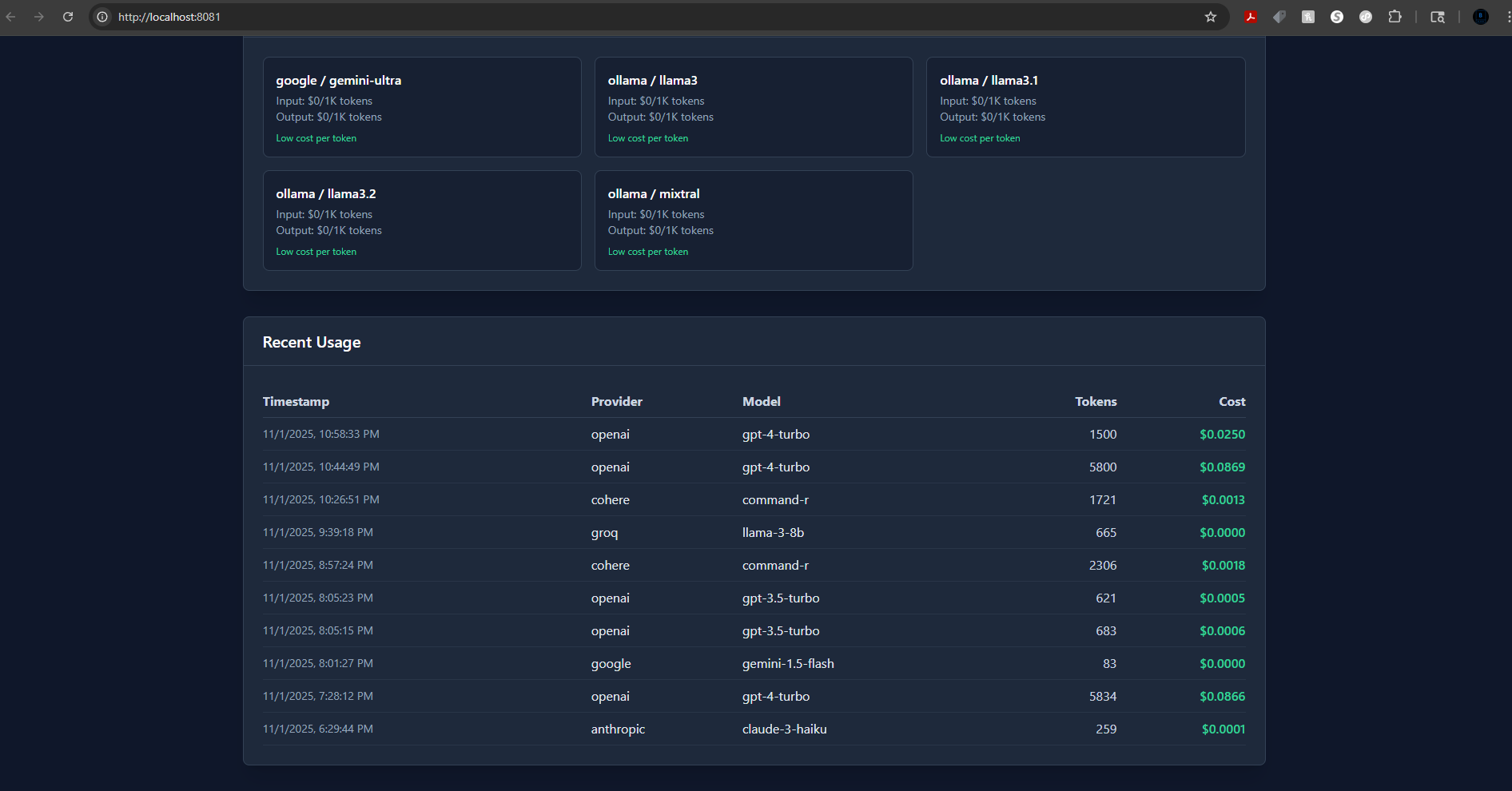
Get intelligent recommendations for cheaper model alternatives:
- Cheapest models first - Groq’s Llama-3-8B at $0.000065/1K tokens
- Side-by-side pricing - Compare input/output costs instantly
- Recent usage history - Track your last 100 API calls
- Save money automatically - Identify where you’re overspending
🔐 Privacy-First & Self-Hosted
- 100% local - Your data never leaves your infrastructure
- No external dependencies - Runs entirely on Docker
- Open source - Audit every line of code
🔌 API Reference
Log API Usage (POST)
Endpoint: POST http://localhost:8000/api/usage
Request Body:
{
"provider": "openai",
"model": "gpt-4",
"prompt_tokens": 100,
"completion_tokens": 50
}
Response:
{
"status": "logged",
"cost_usd": 0.006,
"timestamp": "2025-11-02T10:30:00Z"
}
Get Cost Summary (GET)
Endpoint: GET http://localhost:8000/api/costs/summary
Response:
{
"total_cost": 15.23,
"total_requests": 1250,
"by_provider": {
"openai": 12.45,
"anthropic": 2.78
},
"by_model": {
"gpt-4": 10.20,
"gpt-3.5-turbo": 2.25,
"claude-3-sonnet": 2.78
}
}
Get Model Recommendations (GET)
Endpoint: GET http://localhost:8000/api/recommendations
Returns a list of LLM models sorted by cost (cheapest first) with pricing details.
Interactive API Docs
Visit http://localhost:8000/docs for full interactive API documentation.
⚙️ Configuration
Create a .env file:
DATABASE_PATH=./data/llmscope.db
LLMSCOPE_API_KEY=your-secret-key
🏗️ Architecture
┌─────────────────┐
│ Frontend │ React + Vite
│ (Port 8081) │ Cost dashboard
└────────┬────────┘
│
│ HTTP/REST
│
┌────────▼────────┐
│ Backend API │ FastAPI + SQLite
│ (Port 8000) │ Cost tracking
└─────────────────┘
📦 Tech Stack
Backend:
- FastAPI
- SQLite
- Python 3.9+
Frontend:
- React
- Vite
- Tailwind CSS
Deployment:
- Docker
- Docker Compose
🗄️ Database Schema
api_usage
Tracks all API calls with token counts and costs
model_pricing
Stores pricing data for different LLM models
settings
Application configuration
🛠️ Development
# Backend tests
cd backend
pytest
# Frontend development
cd frontend
npm run dev
# Production build
docker-compose -f docker-compose.prod.yml up -d
🗺️ Roadmap
Supported Providers: OpenAI, Anthropic, Google, Cohere, Together AI, Mistral, Groq, Ollama, and 60+ models
Coming Soon:
- Cost alerts and budget thresholds
- Export to CSV/PDF
- More provider integrations (request yours in Issues!)
Want to influence the roadmap? Open an issue or start a discussion!
🤝 Contributing
Contributions are welcome! Please feel free to submit a Pull Request.
📄 License
Business Source License 1.1
✅ Free for Non-Commercial Use
- ✅ Self-hosting for personal use, education, and research
- ✅ Modify and redistribute for non-commercial purposes
- ✅ Full source code access - no restrictions on reading the code
💼 Commercial Use Requires License
Commercial use includes:
- Using LLMscope to monitor production LLM deployments in a business
- Offering LLMscope as a hosted/managed service to customers
- Incorporating LLMscope into a commercial product
Need a commercial license? Contact: bbaker@blb3dprinting.com
🔓 Future: Converts to MIT License
On October 29, 2028 (3 years from first publication), this license automatically converts to MIT - making it fully open source forever.
Why BSL? We want LLMscope to be freely available for individuals and small teams, while ensuring companies using it commercially contribute back. This allows us to keep developing new features like SPC analysis, AI copilot, and enhanced reporting.
💬 Support
- GitHub Issues: Report bugs or request features
- Discussions: Ask questions
Built with ❤️ for the LLM community